warstwa aplikacji
Nasze serwisy prasowe oparte są na przebudowanej, komercyjnej aplikacji InBefore. Ulepszeń w stosunku do oryginału jest bardzo dużo, ale:
- utrzymujemy pełną kompatybilność na poziomie schematu bazy danych (dodaliśmy sporo dodatkowych tabel, kolumn i indeksów, natomiast modyfikacje oryginalnych obiektów sprowadzają się do zmiany typów 2 tabel na InnoDB)
- utrzymujemy identyczny schemat routingu do poszczególnych typów podstron
- utrzymujemy identyczną strukturę ścieżek do plików (obrazków, JS, CSS, elementów szablonu i tłumaczeń)
- nie robimy żadnych zmian w oryginalnych plikach JS i CSS, a oryginalne style CSS nadpisujemy własnymi, podpinanymi w osobnych plikach
- zmiany w kodzie szablonów (katalog
site/themes/default) są stosunkowo niewielkie i punktowe
Dzięki temu, jeśli chcesz zacząć eksperymenty z układem strony jeszcze przed nawiązaniem współpracy z nami, możesz zacząć od zakupu oryginalnej wersji InBefore, a potem na swój kod nanieść nasze zmiany, które otrzymasz w postaci tzw. diffa.
warstwa systemowa
Całość działa na standardowym Ubuntu 22.04 LTS (albo starszej wersji, minimalnie 18.04) i używa klasycznych technologii linuxowych:
- Apache+PHP – jako serwer aplikacji
- Nginx+certbot – jako proxy terminujące SSL
- MySQL – jako baza danych (może być dowolna inna wersja: MariaDB, Percona)
- memcached
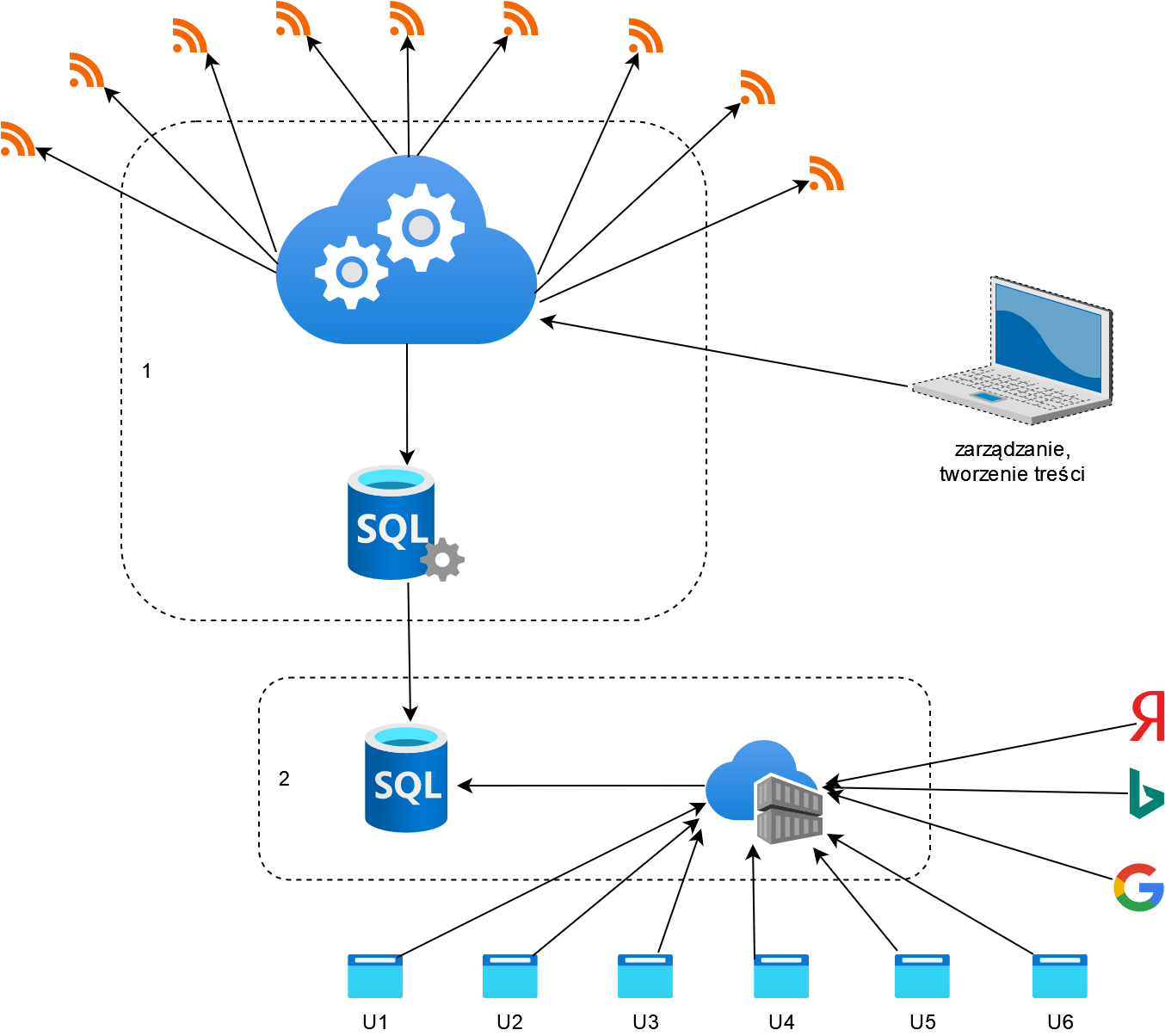
architektura sieciowa
Cała instalacja podzielona jest na dwie osobne maszyny (pokazane wyżej, na zdjęciu tytułowym):
- Nasza maszyna centralna (wspólna dla wszystkich klientów) – tutaj uruchomiony jest importer, strony demonstracyjne, oraz MySQL w trybie master. Tylko ta maszyna kontaktuje się sieciowo z usługami AI.
- Maszyna klienta – tutaj uruchomione są strony klienta, oraz MySQL w trybie slave.
Pomiędzy maszynami uruchomiona jest replikacja zawartości bazy danych, dzięki czemu z maszyny klienta nie wychodzi żaden ruch do stron źródłowych. Klient za pomocą replikacji dostaje gotowy do użytku strumień świeżych artykułów.
Klienci końcowi, oraz crawlery wyszukiwarek, łączą się wyłącznie do maszyny 2. Maszyny 1 i 2 nie są w żaden sposób powiązane nazwami domen ani adresami IP.
wymagania systemowe
Dzięki bardzo niewielkiej liczbie zmian w raz zindeksowanych treściach, a dzięki temu, bardzo skutecznemu buforowaniu danych, wymagania odnośnie serwera są bardzo niskie. W tej chwili:
- ponad 20 stron demonstracyjnych
- działający przez cały czas importer
- ponad 4 tysiące skonfigurowanych źródeł, prawie 2 miliony zindeksowanych artykułów
- różne integracje zewnętrzne
- i jeszcze kilka narzędzi wewnętrznych
bez problemu działają na maszynach mających po 2 vCPU i 4 GB RAM (dokładnie na modelach CX21 w Hetzner Cloud, za € 6.58 brutto miesięcznie za sztukę).